NVIDIA NeMo Framework

Technische Daten
- Produktname: NVIDIA NeMo Framework
- Betroffene Plattformen: Windows, Linux, macOS
- Betroffene Versionen: Alle Versionen vor 24
- Sicherheitslücke: CVE-2025-23360
- Basisbewertung der Risikobewertung: 7.1 (CVSS v3.1)
Anweisungen zur Produktverwendung
Installation des Sicherheitsupdates:
Um Ihr System zu schützen, befolgen Sie diese Schritte:
- Laden Sie die neueste Version von der NeMo-Framework-Launcher-Releases-Seite auf GitHub herunter.
- Weitere Informationen finden Sie unter NVIDIA-Produktsicherheit.
Details zum Sicherheitsupdate:
Das Sicherheitsupdate behebt eine Schwachstelle im NVIDIA NeMo Framework, die zur Ausführung von Code und zur Datenübertragung führen könnte.ampRing.
Software Upgrade:
Wenn Sie eine frühere Zweigversion verwenden, wird empfohlen, auf die neueste Zweigversion zu aktualisieren, um das Sicherheitsproblem zu beheben.
Überview
NVIDIA NeMo Framework ist ein skalierbares und Cloud-natives generatives KI-Framework für Forscher und Entwickler, die an Große Sprachmodelle, Multimodal und Sprach-KI (z.B Automatische Spracherkennung Und Text-zu-Sprache). Es ermöglicht Benutzern, neue generative KI-Modelle effizient zu erstellen, anzupassen und bereitzustellen, indem sie vorhandenen Code und vorab trainierte Modell-Checkpoints nutzen.
Installationsanweisungen: NeMo Framework installieren
NeMo Framework bietet umfassende Unterstützung für die Entwicklung von Large Language Models (LLMs) und Multimodal Models (MMs). Es bietet die Flexibilität, vor Ort, im Rechenzentrum oder bei Ihrem bevorzugten Cloud-Anbieter eingesetzt zu werden. Es unterstützt außerdem die Ausführung in SLURM- oder Kubernetes-fähigen Umgebungen.

Datenkuratierung
NeMo-Kurator [1] ist eine Python-Bibliothek mit einer Reihe von Modulen für Data Mining und die Generierung synthetischer Daten. Sie sind skalierbar und für GPUs optimiert, wodurch sie sich ideal für die Kuratierung natürlicher Sprachdaten zum Trainieren oder Optimieren von LLMs eignen. Mit NeMo Curator können Sie effizient hochwertigen Text aus umfangreichen Rohdaten extrahieren. web Datenquellen.
Schulung und Anpassung
NeMo Framework bietet Werkzeuge für effizientes Training und Anpassung von LL.M.-Studiengänge und multimodale Modelle. Es enthält Standardkonfigurationen für die Einrichtung von Rechenclustern, den Datendownload und Modell-Hyperparameter, die für das Training mit neuen Datensätzen und Modellen angepasst werden können. Neben dem Vortraining unterstützt NeMo sowohl Supervised Fine-Tuning (SFT) als auch Parameter Efficient Fine-Tuning (PEFT)-Techniken wie LoRA, Ptuning und mehr.
Zum Starten des Trainings in NeMo stehen zwei Optionen zur Verfügung: über die NeMo 2.0 API-Schnittstelle oder mit NeMo Run.
- Mit NeMo Run (empfohlen): NeMo Run bietet eine Schnittstelle zur optimierten Konfiguration, Ausführung und Verwaltung von Experimenten in verschiedenen Rechenumgebungen. Dies umfasst das Starten von Jobs auf Ihrer Workstation lokal oder in großen Clustern – sowohl SLURM-fähig als auch Kubernetes in einer Cloud-Umgebung.
- Vortraining & PEFT-Schnellstart mit NeMo Run
- Verwenden der NeMo 2.0-API: Diese Methode eignet sich gut für einfache Konfigurationen mit kleinen Modellen oder wenn Sie Ihren eigenen benutzerdefinierten Datenlader, Trainingsschleifen oder Änderungsmodellebenen schreiben möchten. Sie bietet Ihnen mehr Flexibilität und Kontrolle über Konfigurationen und erleichtert die programmgesteuerte Erweiterung und Anpassung von Konfigurationen.
-
TraSchnellstart mit NeMo 2.0 API
-
Migration von NeMo 1.0 zur NeMo 2.0 API
-
Ausrichtung
- NeMo-Aligner [1] ist ein skalierbares Toolkit für effiziente Modellausrichtung. Das Toolkit unterstützt modernste Modellausrichtungsalgorithmen wie SteerLM, DPO, Reinforcement Learning from Human Feedback (RLHF) und vieles mehr. Diese Algorithmen ermöglichen es Benutzern, Sprachmodelle sicherer, harmloser und hilfreicher auszurichten.
- Alle NeMo-Aligner-Checkpoints sind mit dem NeMo-Ökosystem kompatibel, was eine weitere Anpassung und Inferenzbereitstellung ermöglicht.
Schrittweiser Arbeitsablauf aller drei Phasen von RLHF an einem kleinen GPT-2B-Modell:
- SFT-Schulung
- Training zum Belohnungsmodell
- PPO-Schulung
Darüber hinaus demonstrieren wir die Unterstützung verschiedener anderer neuartiger Ausrichtungsmethoden:
- Datenschutzbeauftragter: ein im Vergleich zu RLHF leichter Ausrichtungsalgorithmus mit einer einfacheren Verlustfunktion.
- Selbstspiel Feinabstimmung (SPIN)
- SteerLM: eine auf konditionierter SFT basierende Technik mit steuerbarer Ausgabe.
Weitere Informationen finden Sie in der Dokumentation: Ausrichtungsdokumentation
Multimodale Modelle
- NeMo Framework bietet optimierte Software zum Trainieren und Bereitstellen modernster multimodaler Modelle in mehreren Kategorien: Multimodale Sprachmodelle, Vision-Language-Grundlagen, Text-zu-Bild-Modelle und darüber hinaus 2D-Generierung mithilfe von Neural Radiance Fields (NeRF).
- Jede Kategorie ist darauf ausgelegt, den spezifischen Anforderungen und Fortschritten auf dem jeweiligen Gebiet gerecht zu werden. Dabei kommen modernste Modelle zum Einsatz, um eine große Bandbreite an Datentypen zu verarbeiten, darunter Text, Bilder und 3D-Modelle.
Notiz
Wir migrieren die Unterstützung für multimodale Modelle von NeMo 1.0 auf NeMo 2.0. Wenn Sie sich in der Zwischenzeit mit diesem Bereich vertraut machen möchten, lesen Sie bitte die Dokumentation zur vorherigen Version von NeMo 24.07.
Bereitstellung und Inferenz
NeMo Framework bietet verschiedene Pfade für die LLM-Inferenz und berücksichtigt dabei unterschiedliche Bereitstellungsszenarien und Leistungsanforderungen.
Bereitstellung mit NVIDIA NIM
- NeMo Framework lässt sich über NVIDIA NIM nahtlos in unternehmensweite Modellbereitstellungstools integrieren. Diese Integration basiert auf NVIDIA TensorRT-LLM und gewährleistet optimierte und skalierbare Inferenz.
- Weitere Informationen zu NIM finden Sie auf der NVIDIA-Website. webWebsite.
Bereitstellen mit TensorRT-LLM oder vLLM
- NeMo Framework bietet Skripte und APIs zum Exportieren von Modellen in zwei für Inferenz optimierte Bibliotheken, TensorRT-LLM und vLLM, und zum Bereitstellen des exportierten Modells mit dem NVIDIA Triton Inference Server.
- Für Szenarien, die eine optimierte Leistung erfordern, können NeMo-Modelle TensorRT-LLM nutzen, eine spezielle Bibliothek zur Beschleunigung und Optimierung der LLM-Inferenz auf NVIDIA-GPUs. Dabei werden NeMo-Modelle mithilfe des Moduls nemo.export in ein mit TensorRT-LLM kompatibles Format konvertiert.
- LLM-Bereitstellung abgeschlossenview
- Stellen Sie NeMo Large Language Models mit NIM bereit
- Stellen Sie NeMo Large Language Models mit TensorRT-LLM bereit
- Bereitstellen von NeMo Large Language Models mit vLLM
Unterstützte Modelle
Große Sprachmodelle
| Große Sprachmodelle | Vortraining und SFT | PEFT | Ausrichtung | FP8-Trainingskonvergenz | TRT/TRTLLM | Konvertieren in und aus Hugging Face | Auswertung |
|---|---|---|---|---|---|---|---|
| Llama3 8B/70B, Llama3.1 405B | Ja | Ja | x | Ja (teilweise verifiziert) | Ja | Beide | Ja |
| Mixtral 8x7B/8x22B | Ja | Ja | x | Ja (nicht verifiziert) | Ja | Beide | Ja |
| Nemotron 3 8B | Ja | x | x | Ja (nicht verifiziert) | x | Beide | Ja |
| Nemotron 4 340B | Ja | x | x | Ja (nicht verifiziert) | x | Beide | Ja |
| Baichuan2 7B | Ja | Ja | x | Ja (nicht verifiziert) | x | Beide | Ja |
| ChatGLM3 6B | Ja | Ja | x | Ja (nicht verifiziert) | x | Beide | Ja |
| Gemma 2B/7B | Ja | Ja | x | Ja (nicht verifiziert) | Ja | Beide | Ja |
| Gemma2 2B/9B/27B | Ja | Ja | x | Ja (nicht verifiziert) | x | Beide | Ja |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Ja | Ja | x | Ja (nicht verifiziert) | x | x | Ja |
| Phi3 mini 4k | x | Ja | x | Ja (nicht verifiziert) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Ja | Ja | x | Ja (nicht verifiziert) | Ja | Beide | Ja |
| StarCoder 15B | Ja | Ja | x | Ja (nicht verifiziert) | Ja | Beide | Ja |
| StarCoder2 3B/7B/15B | Ja | Ja | x | Ja (nicht verifiziert) | Ja | Beide | Ja |
| BERT 110M/340M | Ja | Ja | x | Ja (nicht verifiziert) | x | Beide | x |
| T5 220M/3B/11B | Ja | Ja | x | x | x | x | x |
Vision Language-Modelle
| Vision Language-Modelle | Vortraining und SFT | PEFT | Ausrichtung | FP8-Trainingskonvergenz | TRT/TRTLLM | Konvertieren in und aus Hugging Face | Auswertung |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | Ja | Ja | x | Ja (nicht verifiziert) | x | Aus | x |
| Llama 3.2 Vision 11B/90B | Ja | Ja | x | Ja (nicht verifiziert) | x | Aus | x |
| LLaVA Weiter (LLaVA 1.6) | Ja | Ja | x | Ja (nicht verifiziert) | x | Aus | x |
Einbettungsmodelle
| Einbetten von Sprachmodellen | Vortraining und SFT | PEFT | Ausrichtung | FP8-Trainingskonvergenz | TRT/TRTLLM | Konvertieren in und aus Hugging Face | Auswertung |
|---|---|---|---|---|---|---|---|
| SBERT 340M | Ja | x | x | Ja (nicht verifiziert) | x | Beide | x |
| Lama 3.2 Einbettung 1B | Ja | x | x | Ja (nicht verifiziert) | x | Beide | x |
Weltstiftungsmodelle
| Weltstiftungsmodelle | Nach dem Training | Beschleunigte Inferenz |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Ja | Ja |
| Cosmos-1.0-Diffusion-Text2World-14B | Ja | Ja |
| Cosmos-1.0-Diffusion-Video2World-7B | Demnächst verfügbar | Demnächst verfügbar |
| Cosmos-1.0-Diffusion-Video2World-14B | Demnächst verfügbar | Demnächst verfügbar |
| Cosmos-1.0-Autoregressive-4B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-5B | Demnächst verfügbar | Demnächst verfügbar |
| Cosmos-1.0-Autoregressive-12B | Ja | Ja |
| Cosmos-1.0-Autoregressive-Video2World-13B | Demnächst verfügbar | Demnächst verfügbar |
Notiz
NeMo unterstützt auch das Vortraining für Diffusions- und autoregressive Architekturen text2world Gründungsmodelle.
Sprach-KI
Die Entwicklung von Konversations-KI-Modellen ist ein komplexer Prozess, der die Definition, Konstruktion und Schulung von Modellen in bestimmten Domänen umfasst. Dieser Prozess erfordert typischerweise mehrere Iterationen, um ein hohes Maß an Genauigkeit zu erreichen. Oftmals sind mehrere Iterationen erforderlich, um eine hohe Genauigkeit zu erreichen, verschiedene Aufgaben und domänenspezifische Daten zu optimieren, die Trainingsleistung sicherzustellen und Modelle für den Inferenzeinsatz vorzubereiten.
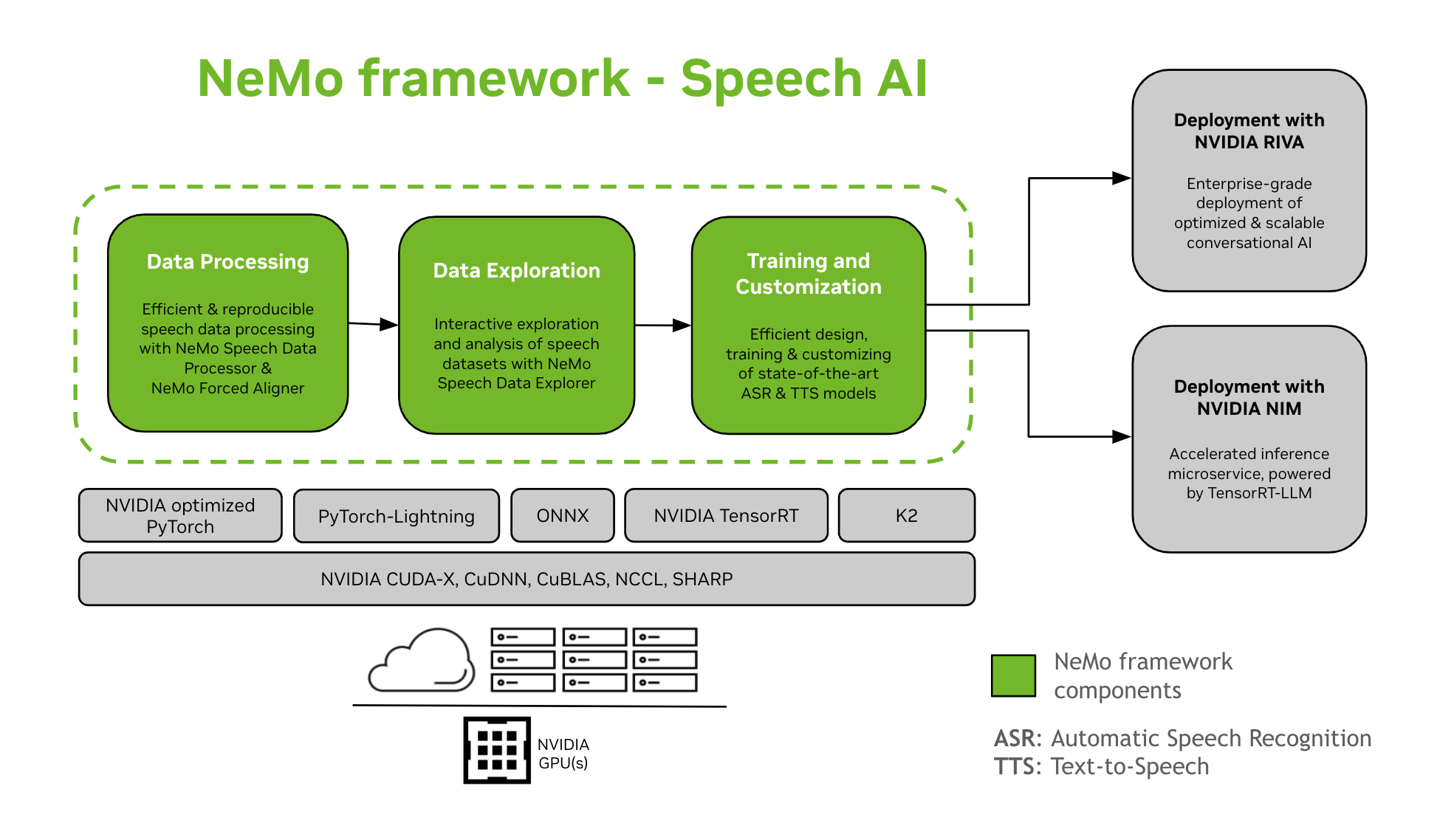
NeMo Framework unterstützt das Training und die Anpassung von Sprach-KI-Modellen. Dies umfasst Aufgaben wie automatische Spracherkennung (ASR) und Text-to-Speech (TTS)-Synthese. Es ermöglicht einen reibungslosen Übergang zur unternehmensweiten Produktionsbereitstellung mit NVIDIA Riva. Zur Unterstützung von Entwicklern und Forschern umfasst NeMo Framework modernste vortrainierte Prüfpunkte, Tools für die reproduzierbare Sprachdatenverarbeitung sowie Funktionen zur interaktiven Exploration und Analyse von Sprachdatensätzen. Die Komponenten des NeMo Frameworks für Sprach-KI sind:
Schulung und Anpassung
NeMo Framework enthält alles, was zum Trainieren und Anpassen von Sprachmodellen benötigt wird (ASR, Sprachklassifizierung, Sprechererkennung, Sprecherdiarisierung, Und TTS) reproduzierbar.
Vortrainierte SOTA-Modelle
- NeMo Framework bietet modernste Rezepte und vortrainierte Checkpoints mehrerer ASR Und TTS Modelle sowie Anweisungen zum Laden dieser.
- Sprachtools
- NeMo Framework bietet eine Reihe nützlicher Tools für die Entwicklung von ASR- und TTS-Modellen, darunter:
- NeMo Forced Aligner (NFA) zur Generierung von Zeitstempeln auf Token-, Wort- und Segmentebeneamps von Sprache in Audio mithilfe der CTC-basierten automatischen Spracherkennungsmodelle von NeMo.
- Sprachdatenprozessor (SDP), ein Toolkit zur Vereinfachung der Sprachdatenverarbeitung. Es ermöglicht die Darstellung von Datenverarbeitungsvorgängen in einer Konfiguration file, wodurch Boilerplate-Code minimiert und Reproduzierbarkeit und Teilbarkeit ermöglicht werden.
- Sprachdaten-Explorer (SDE), ein Dash-basiertes web Anwendung zur interaktiven Erkundung und Analyse von Sprachdatensätzen.
- Tool zur Datensatzerstellung bietet die Funktion, lange Audiodateien auszurichten files mit den entsprechenden Transkripten und teilen Sie sie in kürzere Fragmente auf, die für das Training des Modells zur automatischen Spracherkennung (ASR) geeignet sind.
- Vergleichstool für ASR-Modelle, um Vorhersagen verschiedener ASR-Modelle auf Wortgenauigkeits- und Äußerungsebene zu vergleichen.
- ASR-Evaluator zur Bewertung der Leistung von ASR-Modellen und anderen Funktionen wie der Sprachaktivitätserkennung.
- Textnormalisierungstool zum Konvertieren von Text von der geschriebenen in die gesprochene Form und umgekehrt (z. B. „31.“ vs. „einunddreißigster“).
- Pfad zur Bereitstellung
- NeMo-Modelle, die mit dem NeMo Framework trainiert oder angepasst wurden, können mit NVIDIA Riva optimiert und bereitgestellt werden. Riva bietet Container und Helm-Charts, die speziell für die Automatisierung der Push-Button-Bereitstellung entwickelt wurden.
Andere Ressourcen
- NeMo: Das Haupt-Repository für das NeMo Framework
- NeMo–Laufen: Ein Tool zum Konfigurieren, Starten und Verwalten Ihrer Machine-Learning-Experimente.
- NeMo-Aligner: Skalierbares Toolkit für effiziente Modellausrichtung
- NeMo-Kurator: Skalierbares Toolkit zur Datenvorverarbeitung und -kuratierung für LLMs
Beteiligen Sie sich an der NeMo-Community, stellen Sie Fragen, holen Sie sich Unterstützung oder melden Sie Fehler.
- NeMo-Diskussionen
- NeMo-Probleme
Programmiersprachen und Frameworks
- Python: Die Hauptschnittstelle zur Verwendung des NeMo Frameworks
- Pytorch: NeMo Framework basiert auf PyTorch
Lizenzen
- NeMo Github Repo ist unter der Apache 2.0-Lizenz lizenziert
- NeMo Framework ist unter der NVIDIA AI PRODUCT AGREEMENT lizenziert. Durch das Abrufen und Verwenden des Containers akzeptieren Sie die Bedingungen dieser Lizenz.
- Der NeMo Framework-Container enthält Llama-Materialien, die der Meta Llama3 Community-Lizenzvereinbarung unterliegen.
Fußnoten
Derzeit ist die Unterstützung von NeMo Curator und NeMo Aligner für multimodale Modelle in Arbeit und wird in Kürze verfügbar sein.
Häufig gestellte Fragen
F: Wie kann ich überprüfen, ob mein System von der Sicherheitslücke betroffen ist?
A: Sie können überprüfen, ob Ihr System betroffen ist, indem Sie die installierte Version des NVIDIA NeMo Frameworks überprüfen. Liegt sie unter Version 24, ist Ihr System möglicherweise anfällig.
F: Wer hat das Sicherheitsproblem CVE-2025-23360 gemeldet?
A: Das Sicherheitsproblem wurde von Or Peles – JFrog Security gemeldet. NVIDIA dankt für ihren Beitrag.
F: Wie kann ich zukünftige Sicherheitsbulletins erhalten?
A: Besuchen Sie die NVIDIA-Produktsicherheitsseite, um Benachrichtigungen zu Sicherheitsbulletins zu abonnieren und über Produktsicherheitsupdates auf dem Laufenden zu bleiben.
Dokumente / Ressourcen
 |
NVIDIA NeMo Framework [pdf] Benutzerhandbuch NeMo Framework, NeMo, Framework |